Il file Robots.txt
Il file Robots.txt. A che cosa serve ? Come si realizza?
Il file robots.txt è un file di testo, codificato in formato UTF-8, che contiene comandi e direttive che servono ad istruire i motori di ricerca su eventuali restrizioni applicate alle pagine di un sito Internet. Il suo funzionamento si basa sul protocollo REP (Robots Exclusion Protocol), un protocollo che permette di rendere invisibile agli spider (o crawler) dei motori di ricerca l’intero sito web o singole pagine. Uno spider è un software che analizza in maniera metodica ed automatizzata i contenuti dei diversi siti pubblicati su Internet, inserendo le pagine visitate in un indice. Il file robots.txt deve essere caricato nella directory principale del dominio (root directory) e può essere creato attraverso un semplice editor di testo (anche “notepad”). Tutti gli spider dei motori di ricerca che supportano il protocollo REP, se trovano il file robots.txt, seguiranno le direttive contenute al suo interno.
Struttura del file robots.txt
Il file robots.txt contiene dei record, composti da più campi: l’elemento User-agent, che indica a quale robot/spider si applicano i comandi successivi, la direttiva Disallow, che serve ad indicare qual è il contenuto a cui non può accedere lo spider. Si può anche utilizzare la direttiva Allow che fornisce in modo esplicito l’autorizzazione per la scansione di determinati Url. Altre direttive che possono essere inserite nel file robots sono: Sitemap e Crawl-delay.
Uso della direttiva sitemap
Anche se il file robots.txt è stato creato per indicare ai motori di ricerca quali pagine non scansionare, esso può essere utilizzato anche per indirizzare i motori di ricerca alla mappa del sito XML. Questo è supportato da Google, Bing, Yahoo e Ask. La mappa del sito XML deve essere referenziata come URL assoluto. L’URL non deve essere necessariamente sullo stesso host del file robots.txt. Tieni presente che è possibile fare riferimento a più sitemap XML in un file robots.txt.
Uso della direttiva Crawl-delay
La direttiva Crawl-delay è una direttiva, non supportata da tutti i motori di ricerca (Bing, Yahoo and Yandex la supportano, ma non Google), utilizzata per evitare di sovraccaricare i server con troppe richieste. Crawl-delay indica la frequenza di scansione suggerita ai bot di scansione dei motori di ricerca. La soluzione, tuttavia, non è quella di aggiungere la direttiva Crawl-delay al file robots.txt, ma di utilizzare un hosting che abbia performance adeguate al traffico generato dai motori di ricerca sul tuo sito. Se il tuo sito Web è in esecuzione su un ambiente di hosting scadente e/o il tuo sito Web è configurato in modo errato l’utilizzo di tale direttiva è solo una soluzione temporanea. La direttiva Crawl-delay dovrebbe essere inserita subito dopo le direttive Disallow o Allow (vedi esempio).
User-agent: BingBot Disallow: /private/ Crawl-delay: 10
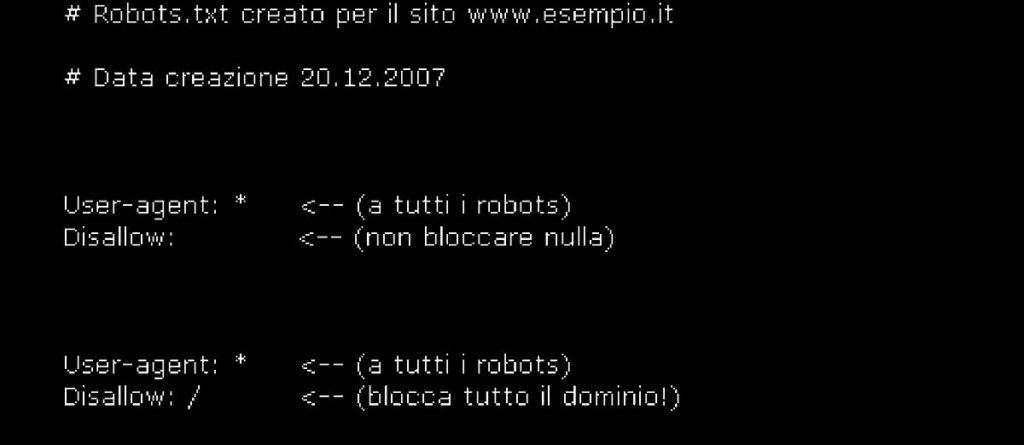
Il simbolo “#” indica semplicemente la dichiarazione di un commento. L’elemento “User-agent” specifica il nome del bot al quale vengono applicate le istruzioni a essa immediatamente successive. Il valore “*” specifica che tale comando viene applicato a tutti i robot/spider, mentre “/” indica che deve essere bloccato il contenuto dell’intero sito web.
Apportare modifiche al robots.txt
Occorre fare molta attenzione quando si apportano modifiche al tuo robots.txt, in quanto potrebbe rendere inaccessibili ai motori di ricerca grandi parti del tuo sito web. Quando si implementa il file robots.txt, è bene tenere a mente le seguenti regole:
- il file robots.txt dovrebbe risiedere nella radice del tuo sito web (ad es. http://www.example.com/robots.txt);
- il file robots.txt è valido solo per l’intero dominio in cui risiede, incluso il protocollo (http o https);
- diversi motori di ricerca interpretano le direttive in modo diverso. Per impostazione predefinita, la prima direttiva corrispondente vince sempre. Ma, con Google e Bing, la specificità prevale;
- evita di utilizzare il più possibile la direttiva crawl-delay per i motori di ricerca.
Creare il file robots.txt
Il file robots.txt può essere creato manualmente utilizzando un comune editor di testo (personalmente uso Notepad++). Se però si vuole evitare di commettere errori si possono usare dei tools online gratuiti per la sua generazione, come ad esempio Robots Text Generator Tool.
Esempi di robots.txt
Per capirne esattamente il funzionamento vediamo alcuni esempi di file robots.txt:
# blocca l’indicizzazione dell’intero sito web a tutti gli spider User-agent: * Disallow: /
# il sito è completamente accessibile a tutti gli spider User-agent: * Disallow: # il sito è accessibile solo al bot di Google User-agent: Googlebot Disallow:
N.B: per consentire l’accesso agli spider/bot indicati dobbiamo lasciare uno spazio vuoto dopo i 2 punti che seguono la dicitura Disallow
# viene impedito l’accesso a tutte le cartelle tranne alla cartella public User-agent: * Disallow: / Allow: /public/
# blocca a Google l'accesso a tutti i file immagine di tipo .PNG User-agent: Googlebot Disallow: /*.png$
# questo file robots.txt blocca del tutto Altavista, non permette a Google l’accesso ad alcuni file e directory e non pone vincoli a tutti gli altri motori di ricerca User-agent: scooter Disallow: / User-agent: googlebot Disallow: /intestazione.html Disallow: /links.html Disallow: /temporanei/ Disallow: /cgi-bin/ User-agent: * Disallow:
Vediamo un ultimo esempio di file robots.txt:
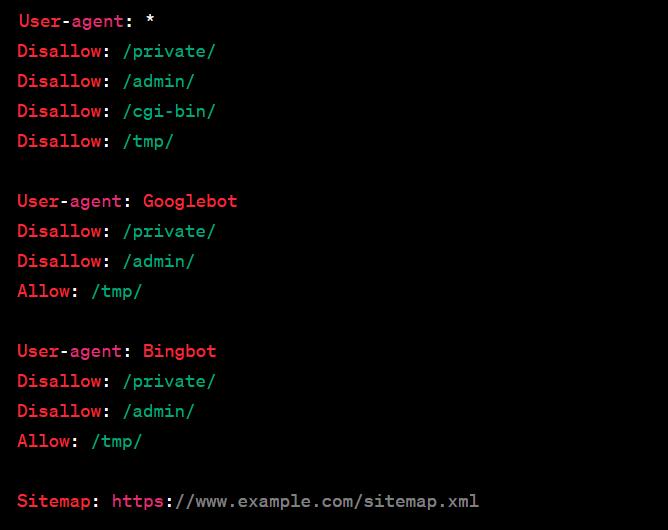
In questo esempio, il file robots.txt contiene alcune direttive per i robot dei motori di ricerca. Di seguito una spiegazione delle direttive utilizzate:
User-agent: *: Si applica a tutti i robot dei motori di ricerca.Disallow: /private/: Impedisce l’accesso alla directory “/private/”.Disallow: /admin/: Impedisce l’accesso alla directory “/admin/”.Disallow: /cgi-bin/: Impedisce l’accesso alla directory “/cgi-bin/”.Disallow: /tmp/: Impedisce l’accesso alla directory “/tmp/”.
Successivamente, ci sono direttive specifiche per i robot di Google (User-agent: Googlebot) e Bing (User-agent: Bingbot), che sono identiche a quelle generali, ma consentono l’accesso alla directory “/tmp/”.
Infine, Sitemap: https://www.example.com/sitemap.xml specifica la posizione del file sitemap XML del sito, che i robot dei motori di ricerca possono utilizzare per individuare e indicizzare le pagine del sito.
Elenco crawler/spider dei principali motori di ricerca
| Nome Robot | Funzione |
|---|---|
| Googlebot | Analizza le pagine web |
| Googlebot-Mobile | Analizza le pagine web per mobile |
| Googlebot-Image | Analizza le immagini |
| Mediapartners-Google | Analizza i contenuti AdSense |
| AdsBot-Google | Analizza i contenuti AdWords |
| Yahoo | |
| Slurp | Analizza le pagine web |
| Yahoo-MMCrawler | Analizza le immagini |
| Yahoo-MMAudVid | Analizza i contenuti video |
| Bing | |
| MSNBot | Analizza le pagine web |
| MSNBot-Media | Analizza i contenuti multimediali |
| MSNBot-News | Analizza i feed delle news |
| Altavista | |
| Scooter | Analizza le pagine web |
| Mercator | |
| Vscooter | Analizza le immagini ed i contenuti multimediali |
Per avere una lista dei nomi dei principali crawler cliccate sul seguente link: lista crawler.
Robots.txt e la SEO
Sebbene le direttive nel file robots.txt siano un segnale forte per i motori di ricerca, è importante ricordare che il file robots.txt è un insieme di direttive facoltative per i motori di ricerca. Se implementato (lo consiglio vivamente) il robots.txt gioca comunque un ruolo importante nell’universo SEO. Esso influenza il modo con cui i motori di ricerca vedono il sito web e come lo presentano poi agli utenti. In sintesi comunica agli user agents (i bot) le tue preferenze di scansione del sito, quindi influisce sull’indicizzazione. Utilizzando il file robots.txt puoi impedire ai motori di ricerca di accedere ad alcune parti del tuo sito web, prevenire la duplicazione di contenuti e fornire ai motori di ricerca suggerimenti utili su come eseguire la scansione del tuo sito web in modo più efficiente.
